
Opus 4.6 vs GPT‑5.3 Codex: What Changed (and Why It Matters)

Table Of Content
- TL;DR
- Table of Contents
- The part nobody says out loud
- Claude Opus 4.6: what actually shipped
- GPT‑5.3‑Codex: what actually shipped
- Side-by-side: where each model wins
- A mental model for choosing (without vibes)
- How we’d run these models inside a “digital workforce”
- Gotchas, failure modes, and governance
- Conclusion
- Sources / Further Reading
Opus 4.6 vs GPT‑5.3 Codex: What Changed (and Why It Matters)
 Figure 1: The comparison that matters in practice: long-horizon autonomy vs supervised delivery loops.
Figure 1: The comparison that matters in practice: long-horizon autonomy vs supervised delivery loops.
TL;DR
- Claude Opus 4.6 is positioned as Anthropic’s flagship for long-running agentic work: bigger effective context, higher max output, and more control over “how hard” it thinks (adaptive + “effort” controls).
- GPT‑5.3‑Codex is OpenAI’s latest push to make Codex feel like a real junior engineer: stronger benchmark results, faster runs (OpenAI claims ~25% faster), and better mid-task steerability.
- The real shift isn’t “coding accuracy.” It’s execution ergonomics: parallel agents, better tool use, and safer ways to run code against real environments.
- If you build with agents, your main decision is: Do you want a model optimized for sustained autonomy (Opus 4.6) or a model optimized for supervised software delivery loops (GPT‑5.3‑Codex)?
Table of Contents
- The part nobody says out loud
- Claude Opus 4.6: what actually shipped
- GPT‑5.3‑Codex: what actually shipped
- Side-by-side: where each model wins
- A mental model for choosing (without vibes)
- How we’d run these models inside a “digital workforce”
- Gotchas, failure modes, and governance
- Conclusion
- Sources / Further Reading
The part nobody says out loud
AI coding models didn’t win because they can write a sorting function.
They’re winning because they can sit inside your stack for hours, keep state, follow constraints, and behave like a teammate you can supervise.
That sounds small until you’ve watched an “agentic” model:
- lose the thread halfway through a multi-file refactor,
- forget the failing test it was supposed to fix,
- or “solve” a bug by deleting the code path that made the bug visible.
The new releases—Opus 4.6 and GPT‑5.3‑Codex—are best understood as competing answers to the same question:
How do we make AI agents reliable enough to trust with real work?
Not “cool demos.” Not “write code.” Real work.
Claude Opus 4.6: what actually shipped
Anthropic’s framing is pretty direct: Opus 4.6 is built for coding and long-running professional tasks, especially in agentic setups.
1) Bigger context (and a path to much bigger)
According to the Claude API docs, Opus 4.6 supports a 200K context window, with a 1M token context window available in beta. It also supports up to 128K output tokens—which matters when your agent needs to produce large diffs, long reports, or multi-step plans in a single run.
That 128K output cap is not a vanity metric. It’s the difference between:
- “Here’s the patch”
- and “Here are 38 partial patches across 14 messages, good luck reconciling them.”
2) “Adaptive thinking” + effort controls
The Opus 4.6 system card introduces an adaptive thinking mode (for API customers) where the model can calibrate its reasoning depth based on the task. Claude’s “what’s new” docs also mention a new max effort level for Opus 4.6.
In practice, this is the beginning of a control surface that matters for production:
- you don’t want maximum depth on every request (cost + latency),
- but you do want it when the agent is about to touch billing logic.
3) Multi-agent “teams” in Claude Code (preview)
Anthropic also connected the model release to product UX: in Claude Code, release notes reference an agent teams feature (research preview) that enables multi-agent workflows.
That’s a clue about where they’re going:
- the model isn’t just “smart,”
- it’s expected to run as a coordinated set of workers.
4) Pricing: staying flat while capability rises
Anthropic says pricing remains $5 / MTok input and $25 / MTok output for Opus 4.6 (per their release post).
This is an underrated part of the story: when capability rises without a pricing spike, you can justify giving the model more autonomy—because your costs are more predictable.
Note: Anthropic also indicates premium pricing can apply for prompts beyond certain context thresholds (see release/pricing pages for details).
GPT‑5.3‑Codex: what actually shipped
OpenAI’s release reads like a product team that has watched thousands of developers try to use agents… and get stuck in the same places.
1) Benchmark posture: SWE‑Bench Pro, Terminal‑Bench, OSWorld, GDPval
OpenAI positions GPT‑5.3‑Codex as setting a new high bar on SWE‑Bench Pro and Terminal‑Bench, with strong results on OSWorld and GDPval.
Benchmarks aren’t the product, but they signal what the model was trained to do:
- not “write code in a vacuum,”
- but solve tasks that resemble real repo work and terminal-driven execution.
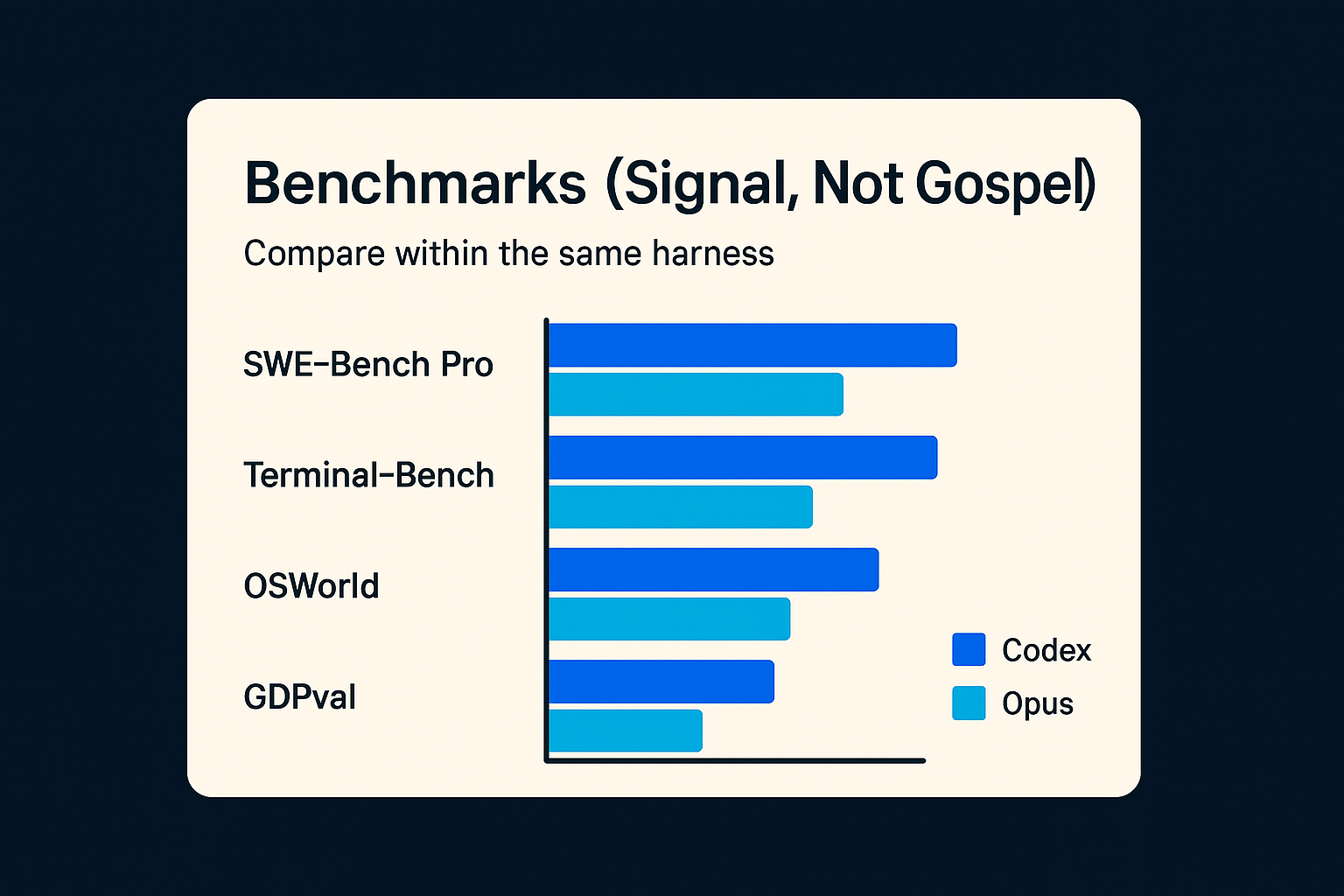 Figure 2: Benchmarks are directionally useful only when you compare within the same harness and assumptions.
Figure 2: Benchmarks are directionally useful only when you compare within the same harness and assumptions.
2) Faster runs
OpenAI says GPT‑5.3‑Codex now runs ~25% faster for Codex users due to infrastructure and inference improvements.
That speed matters because agentic work is often bottlenecked by:
- slow step-by-step tool calls,
- long edit/execute/test loops,
- and the human waiting to approve changes.
A 25% improvement doesn’t sound dramatic until it’s multiplied across a 90-minute autonomous run.
3) Mid-task steerability (why this is a safety feature, not a UX nicety)
A recurring complaint about agent tools: once the model starts running, you either let it finish (and hope), or you stop it (and lose progress).
Codex’s CLI ergonomics are a good example of the “steerability” bet:
- Press Enter while Codex is running to inject new instructions into the current turn.
- Press Tab to queue a follow-up prompt for the next turn.
In other words: you can treat an agent run like a process you can interrupt and shape, not a black box you babysit.
4) Codex as an environment, not a model
OpenAI has been bundling the model improvements with tools:
- a Codex app built around running agent threads in parallel,
- worktree isolation,
- and a workflow that looks closer to a PR factory than a chat box.
If Anthropic is optimizing the model for long-running cognition, OpenAI is optimizing the whole agent harness.
Side-by-side: where each model wins
Here’s the pragmatic read.
 Figure 3: Use-case fit tends to cluster by failure mode: state loss vs execution failure vs supervision friction.
Figure 3: Use-case fit tends to cluster by failure mode: state loss vs execution failure vs supervision friction.
| Dimension | Opus 4.6 | GPT‑5.3‑Codex |
|---|---|---|
| Long-horizon autonomy | Strong emphasis (context + thinking controls) | Strong, but framed more as supervised loops |
| Output size for big diffs/docs | Up to 128K output tokens (per Claude docs) | Depends on Codex surface; optimized for iterated PR workflow |
| Terminal/tool execution | Supported, plus Claude Code ecosystem | Core identity (Terminal‑Bench + Codex CLI/app focus) |
| UX / control | Agent teams (preview) | Steer mode + parallel threads + app/CLI ergonomics |
| Safety framing | System card emphasizes broad evals; safety posture highlighted | System card addendum and mitigations focus on deployment risk |
If you’re a founder/operator buying outcomes, this table maps to:
- Opus 4.6: “Give me a worker that can hold the whole system in its head.”
- GPT‑5.3‑Codex: “Give me an agent I can supervise like a dev: branch, diff, test, PR.”
A mental model for choosing (without vibes)
Most teams pick models like they pick running shoes: whatever their friends say is fastest.
Pick based on your failure mode.
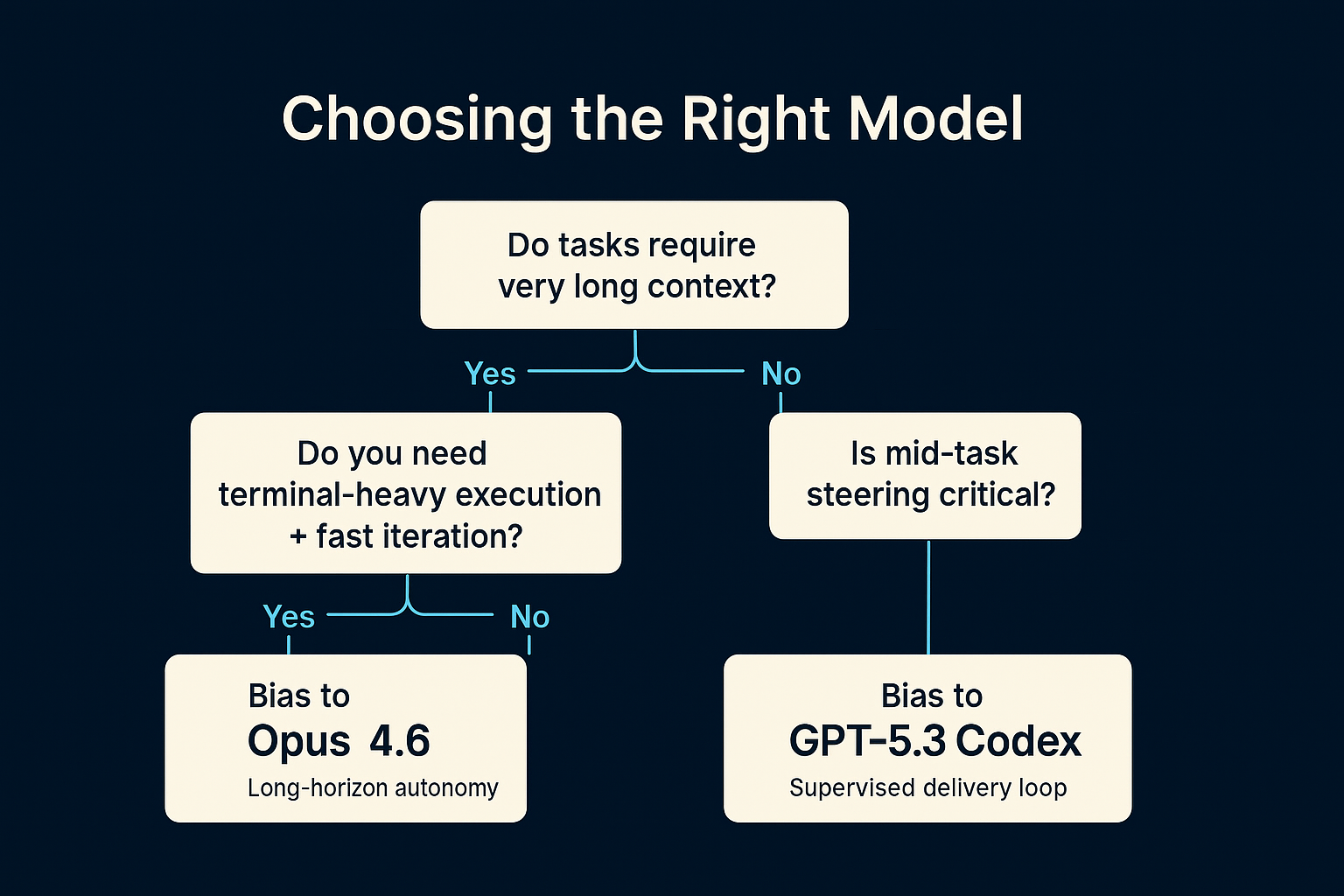 Figure 4: A simple decision tree that forces you to name your constraints instead of arguing about vibes.
Figure 4: A simple decision tree that forces you to name your constraints instead of arguing about vibes.
Failure mode A: The model loses state
Symptoms:
- It forgets why it’s changing files.
- It drifts across requirements.
Bias toward: Opus 4.6 (context + long-horizon planning posture).
Failure mode B: The model can’t execute reliably
Symptoms:
- It writes code that “should work,” but can’t run tests.
- It can’t handle terminal iteration and dependency mess.
Bias toward: GPT‑5.3‑Codex (terminal + agent harness posture).
Failure mode C: Humans can’t supervise it
Symptoms:
- It runs for 30 minutes and you don’t know what it’s doing.
- You can’t inject corrections without nuking the run.
Bias toward: the ecosystem (Codex steer mode + parallel threads; Claude agent teams as it matures).
How we’d run these models inside a “digital workforce”
Most companies will end up using both, because they’re optimized for different job descriptions.
Here’s a simple architecture that matches how real ops teams think.
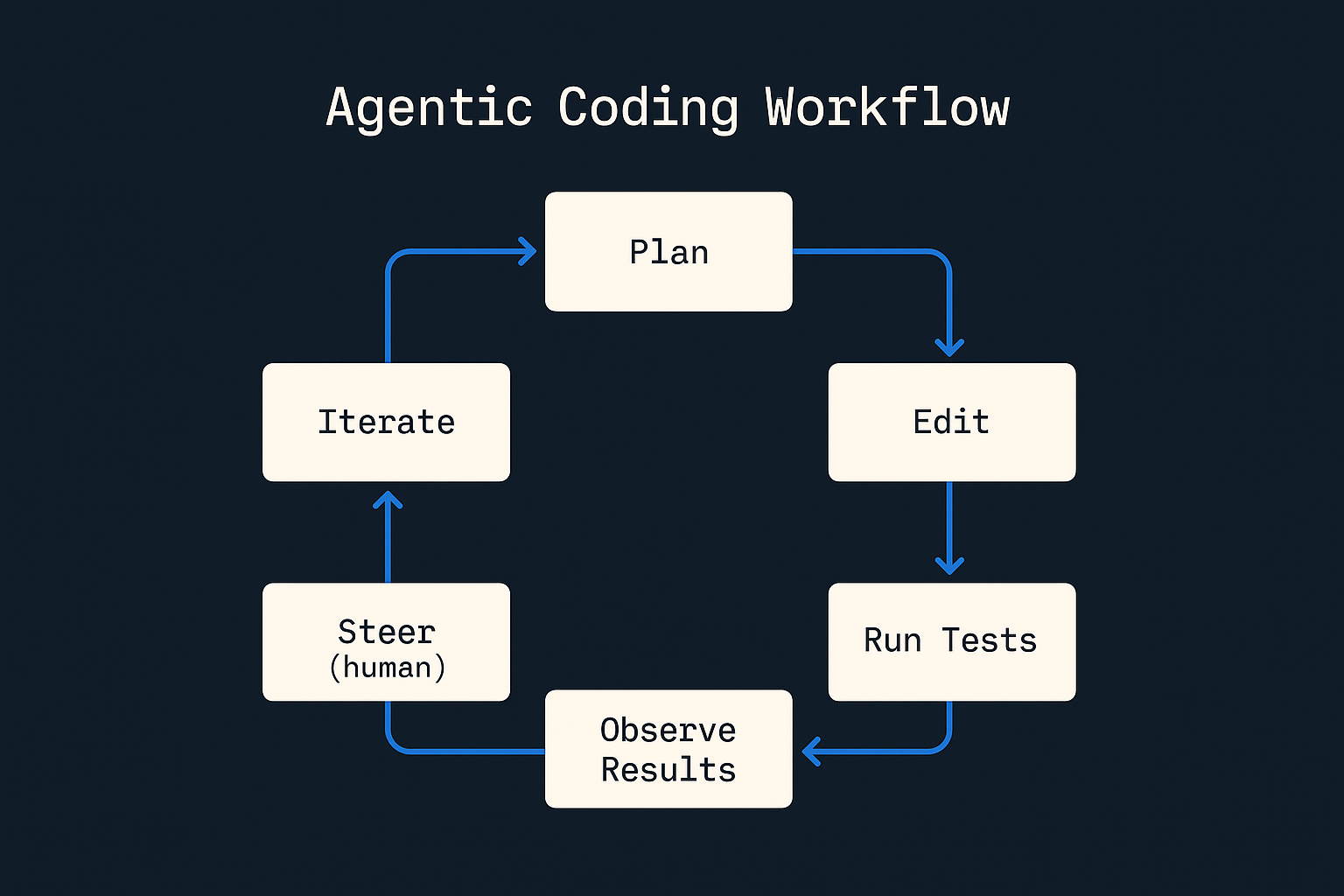 Figure 5: The loop you actually run in production: plan → change → test → observe → steer → iterate.
Figure 5: The loop you actually run in production: plan → change → test → observe → steer → iterate.
This is the “boring” future:
- one worker writes the spec,
- another worker implements,
- and a human stays in the loop at the only moment that actually matters: merge authority.
Where teams get this wrong (and why “model choice” can’t save you)
If you’ve tried agentic coding and bounced off it, it usually wasn’t because the model was 3% worse on a leaderboard. It was because the workflow was missing guardrails.
The failure pattern looks like this:
- You ask for a change that touches too many surfaces.
- The agent makes wide edits.
- Tests are slow or flaky.
- A human loses confidence and starts micromanaging.
- The loop collapses back into “chat that writes snippets.”
When you fix the workflow, model differences start to matter.
A practical rubric: task-to-model mapping
If you want a quick way to assign work without bikeshedding, use this mapping:
-
Opus 4.6 for:
- repo-wide reasoning and synthesis (migrations, architecture notes, audit writeups)
- large refactors where requirements are spread across docs + tickets
- long outputs you want in one coherent artifact (runbooks, playbooks, design docs)
-
GPT‑5.3‑Codex for:
- tight implementation loops (branch → diff → test → iterate)
- tasks where the terminal is the truth (deps, build, CI failures)
- “do it again, slightly different” changes across multiple tickets
This is less about intelligence, more about what you’re optimizing for: long-horizon cognition vs supervised execution throughput.
If you’re building with Poly, this orchestration pattern is the core: reliable work, clear gates, auditable decisions.
Gotchas, failure modes, and governance
The more capable the model, the more dangerous the defaults.
 Figure 6: If you can’t explain your agent’s permissions and merge gates, you don’t have “AI coding.” You have a liability.
Figure 6: If you can’t explain your agent’s permissions and merge gates, you don’t have “AI coding.” You have a liability.
1) Bigger context increases your blast radius
If you can feed an agent more of your repo, it can do more damage.
Governance move:
- keep a single source of truth for requirements,
- constrain file scope,
- enforce “no unreviewed merges.”
2) Long outputs can hide mistakes
If an agent can output massive diffs, you’ll miss stuff.
Governance move:
- enforce test coverage,
- require lint + unit tests,
- review diffs in smaller chunks when possible.
3) Tool access is the real permission boundary
The model is not the risk. The credentials are.
Governance move:
- use least privilege,
- separate dev/staging/prod keys,
- log tool calls.
(That’s not theory. It’s table stakes when you treat agents like workforce.)
A simple governance posture you can actually run
Most teams either:
- do nothing (and hope), or
- bolt on compliance theater after the first incident.
A better default is to treat “agentic coding” like privileged infrastructure.
Minimum viable posture:
- Run in a sandbox by default (worktree, container, or a disposable dev env).
- Constrain scope (repo paths + tool permissions per task).
- Make tests mandatory (no green checks, no merge).
- Keep an audit trail (every tool call, every diff, every decision).
- Human merge gate (the only person who can ship is a person).
This is the same shape whether you’re using Codex, Claude Code, Cursor, or anything else.
Conclusion
Opus 4.6 and GPT‑5.3‑Codex are both serious releases.
But they’re solving slightly different problems.
- Opus 4.6 is a bet on sustained cognition: keep the thread, plan deeply, output large, coordinate across agents.
- GPT‑5.3‑Codex is a bet on supervised software delivery: run faster, steer mid-task, ship diffs through a workflow.
If you’re building internal agents in 2026, don’t ask “which model is smarter?”
Ask: Which model fails the way my organization can tolerate?
Sources / Further Reading
- Introducing Claude Opus 4.6 – Anthropic release post (availability, positioning, pricing).
- What’s new in Claude 4.6 (Claude API Docs) – Context, output limits, and new controls.
- Claude Opus 4.6 System Card (PDF) – Safety evaluations and adaptive thinking details.
- Claude Opus 4.6 Pricing – Pricing notes for Opus 4.6.
- Introducing GPT‑5.3‑Codex – OpenAI release post (benchmarks, speed claim).
- Codex changelog (OpenAI Developers) – Product release notes for Codex surfaces.
- Codex CLI features (OpenAI Developers) – Steer mode interaction details.
- Introducing the Codex app (OpenAI) – Multi-agent threads and worktree workflow.
- Addendum to GPT‑5 system card: GPT‑5‑Codex (OpenAI) – Safety and deployment mitigations.
- SWE‑Bench Pro (Public Dataset) – Scale AI – Benchmark context and leaderboard.
- Claude and Codex are now available in public preview on GitHub (GitHub Blog) – Distribution surface expanding for agents.
Want to deploy a governed digital workforce instead of another brittle automation stack?
Book a call: https://agencyofpoly.com/