
The Future of AI Agent Orchestration (Whitepaper)
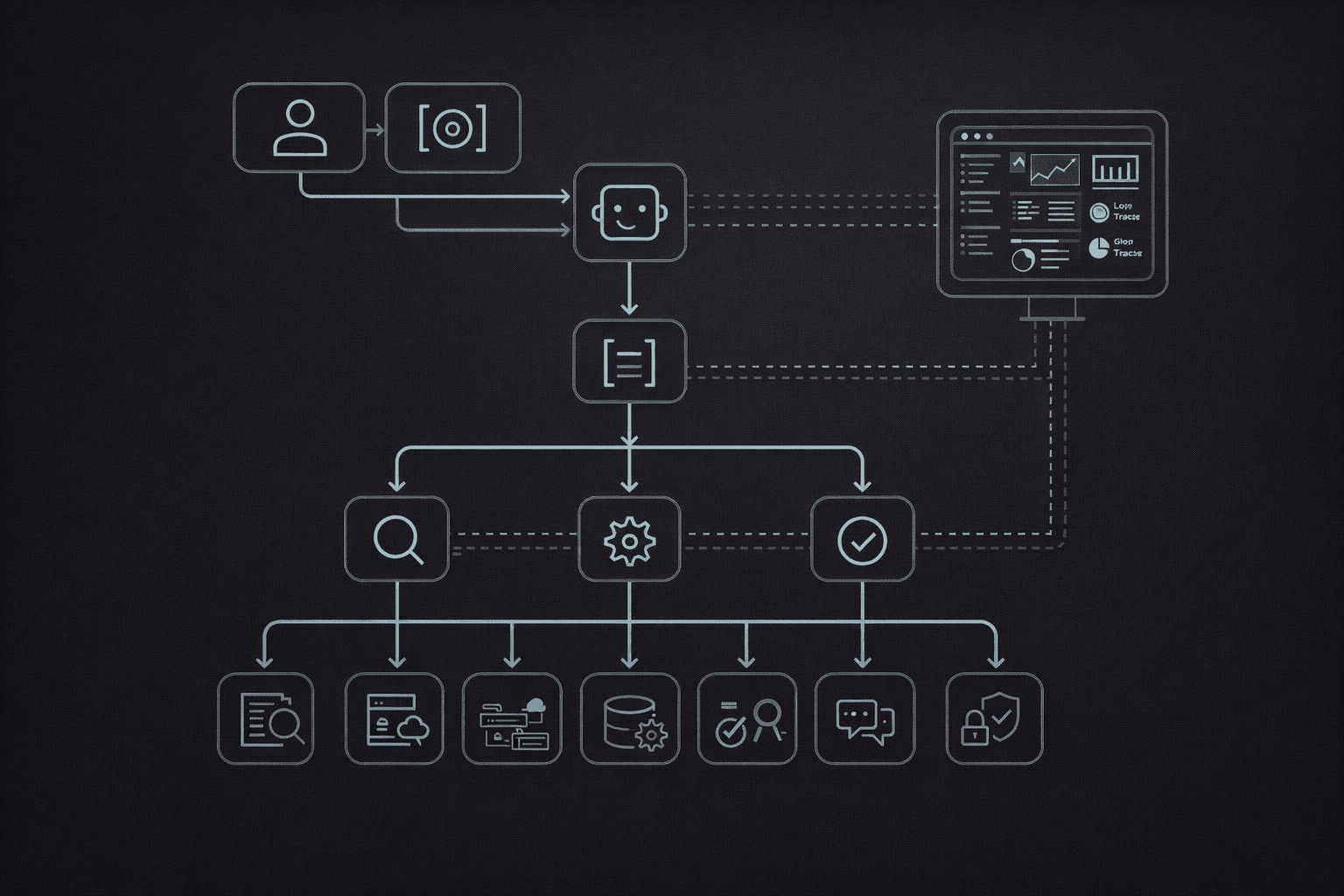
Table Of Content
- TL;DR
- Table of Contents
- Why Orchestration Matters Now
- From Pipelines to Agent Systems
- A Reference Architecture for Orchestration
- Core Capabilities the Next Generation Will Require
- Key Technical Frontiers (2026–2030)
- Frontier A: Standard protocols for agent–tool and agent–agent interaction
- Frontier B: Orchestration as a policy engine
- Frontier C: Multi‑objective optimization of cost, latency, and quality
- Inline Image 2 — Orchestration metrics dashboard
- Frontier D: Runtime grounding and verification
- Frontier E: Long‑horizon tasks and resumability
- Risks, Failure Modes, and Governance
- Implementation Playbook (What to Build This Quarter)
- The Road Ahead
- Call to Action
- Sources
The Future of AI Agent Orchestration
TL;DR
- AI agent orchestration is moving from ad‑hoc “agents in a chat window” to production control planes that manage goals, tools, memory, safety, and evaluation.
- The next generation of stacks will standardize interfaces (tool schemas, agent messaging), runtime controls (policies, rate limits, approvals), and observability (traces, metrics, replay).
- Real value will be measured in business outcomes per dollar—task success rate, cost per successful task, and time‑to‑resolution—not in model benchmarks alone.
- The bottleneck has shifted from raw model quality to system design: state, governance, integration boundaries, and failure handling.
- Teams that win will combine LLM reasoning with deterministic workflows, tests, and governance to ship reliable, auditable agents into real businesses.
Table of Contents
- Why Orchestration Matters Now
- From Pipelines to Agent Systems
- A Reference Architecture for Orchestration
- Core Capabilities the Next Generation Will Require
- Key Technical Frontiers (2026–2030)
- Risks, Failure Modes, and Governance
- Implementation Playbook (What to Build This Quarter)
- The Road Ahead
- Sources
Why Orchestration Matters Now
Agentic AI has crossed an important threshold. In 2023–2025, most organizations experimented with a single “copilot” embedded in a UI. Those pilots were useful—but brittle. As soon as the task required multiple steps, cross‑system coordination, or strict safety constraints, the copilot snapped back to human supervision.
Over the next five years, competitive advantage will not come from “having an LLM.” It will come from deploying agent systems that can consistently complete work under real‑world constraints:
- Multiple tools and data sources
- Heterogeneous users and permissions
- Regulatory and governance requirements
- Budget and latency limits
This is the domain of orchestration.
Orchestration is the layer that turns probabilistic models into deterministic, auditable business processes. It is less about clever prompts and more about how you:
- Translate business goals into machine‑executable tasks
- Route those tasks to the right agents, tools, and models
- Manage state and memory across long‑running workflows
- Monitor, evaluate, and continuously improve performance
Why now?
Several structural shifts have made orchestration urgent rather than optional:
-
Models are powerful but non‑deterministic. Foundation models can reason, plan, and call tools—but their behavior can drift with small context changes or model updates. Without a control plane, this unpredictability is unacceptable in high‑stakes workflows.
-
Tool ecosystems have exploded. From vector databases and CRMs to payment processors and IoT systems, LLMs can now interact with almost any API. This is both an opportunity and a security surface. Orchestration decides who can call what, when, and under which constraints.
-
Expectations have risen. It is no longer enough to demo an agent that books a meeting once. Organizations want:
- 24×7 uptime
- Clear ownership and escalation paths
- Compliance with internal and external policies
- Reliable metrics and SLAs
In this context, “agent orchestration” is best understood as a new kind of application runtime: part workflow engine, part policy engine, part evaluation harness.
From Pipelines to Agent Systems
Traditional automation was largely pipeline‑based:
- Step 1: Trigger (webhook, cron, button)
- Step 2: Deterministic transformations (if this, then that)
- Step 3: Side effects (send an email, write to a database)
This model works when the path from input to output is known in advance. It fails when tasks are open‑ended, under‑specified, or require creative problem solving.
Modern agent systems blend deterministic and probabilistic behavior:
-
Deterministic components:
- State machines and workflow engines
- Validators, schema checkers, and policy guards
- Typed tool interfaces and environment abstractions
-
Probabilistic components:
- Goal interpretation and planning
- Natural language understanding and generation
- Heuristic routing (which agent/model/tool to use)
The evolution typically looks like this:
-
Single LLM + single tool
“Summarize this PDF” or “Translate this text.” Useful, but narrow. -
LLM + tool chains
“Summarize → extract action items → draft follow‑up email.” Here, the orchestration is often baked into a monolithic prompt or a brittle script. -
Planner‑executor loops
Inspired by approaches like ReAct and Toolformer, the model plans a sequence of steps, calls tools, updates its plan, and iterates until completion or a safety limit.[^6][^7] -
Multi‑agent orchestration
Specialized agents (research, execution, QA, routing) collaborate under a control plane. Each agent has clear responsibilities, tools, and constraints. Frameworks like AutoGen, LangGraph, and DSPy embody aspects of this pattern.[^3][^4][^5]
The transition from step 2 to step 4 is where most organizations struggle. Prompt engineering alone is not enough; they need architecture, governance, and metrics.
A Reference Architecture for Orchestration
A practical mental model for orchestration is a control plane above models and tools.
In this architecture:
- Intent & constraints capture what the user wants and under what conditions (budget, latency, tone, compliance rules).
- The Planner agent decomposes the goal into sub‑tasks and decides which agents or tools should handle each part.
- Specialist agents execute: a research agent for retrieval, an execution agent for tool calls and state updates, and a QA/eval agent for checking outputs.
- A Policy & permissions layer governs which tools and data each agent can access.
- A shared State store keeps artifacts, intermediate outputs, and workflow state.
- Observability collects traces and metrics for debugging, evaluation, and governance.
Inline Image 1 — Control‑plane architecture diagram
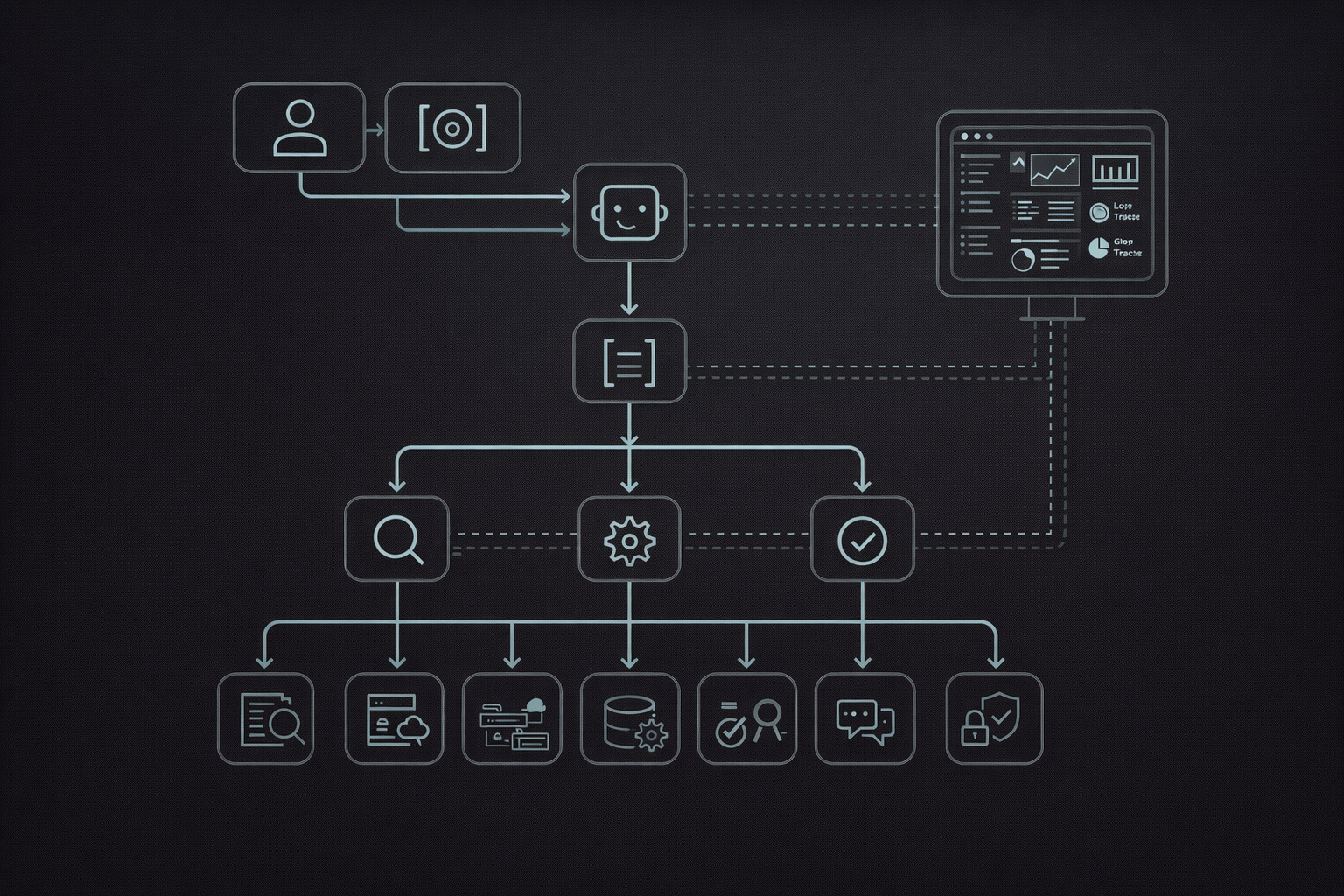
This architectural pattern is emerging across open‑source and commercial stacks. LangGraph, for example, formalizes agents as nodes in a stateful graph, while AutoGen focuses on conversation‑based multi‑agent coordination.[^3][^4] The specifics differ, but the control‑plane idea is consistent.
Core Capabilities the Next Generation Will Require
Future‑ready orchestration platforms will converge on several foundational capabilities.
1) Typed, testable tool calling
“Function calling” and structured outputs have become mainstream in LLM APIs.[^2] The orchestration layer should treat every tool call as:
- Typed: Input and output schemas are explicit and validated.
- Constrained: Guardrails define which tools can be invoked by which agents.
- Observable: Every invocation is logged with parameters, responses, and latency.
- Testable: Tool calls can be replayed in staging environments.
This moves tool use from a free‑form language interface to something closer to program synthesis under constraints. The model proposes; the runtime verifies.
2) State and memory as first‑class citizens
Without robust state management, even sophisticated agent patterns degrade into one‑off chats.
A serious orchestration stack distinguishes between:
- Ephemeral context: The current conversation or task scratchpad.
- Persistent memory: Long‑term user preferences, business facts, and artifacts.
- Workflow state: Which stage a task is in (e.g., drafted → reviewed → approved → shipped).
Research directions like Reflexion and related “self‑reflective” agents highlight the value of storing and reusing prior experiences.[^8] In production, this must be coupled with memory governance:
- What is stored, and for how long?
- Who (and which agents) can read or modify it?
- How is personally identifiable information handled?
3) Routing, specialization, and role clarity
Generalist “do anything” agents are easy to prototype but hard to control. Specialization yields better reliability and governance:
- A router decides which agent or model to use based on task type, user segment, or risk profile.
- Specialist agents (research, drafting, data transformation, policy checking) operate within narrow, testable bounds.
- A judge or critic agent evaluates outputs against checklists, policies, or test cases.
Work in multi‑agent systems (e.g., AutoGen) and agent evaluation (e.g., ReAct‑style planning, Reflexion‑style self‑critique) is converging on this pattern: a mixture of specialists with emergent coordination.[^4][^6][^8]
4) Evaluation‑driven development
The NIST AI Risk Management Framework emphasizes continuous monitoring and improvement of AI systems across the lifecycle.[^9] For agent orchestration, that translates into:
- Offline evaluation: Suites of tasks with expected outputs or reference behaviors.
- Online evaluation: Shadow traffic, canary deployments, and A/B tests.
- Failure taxonomies: A shared language for classifying errors (hallucination, tool misuse, unauthorized access, poor UX).
- Regression testing: Every change in prompts, models, or tools is measured against historical performance.
Over time, the orchestrator itself should become data‑driven: decisions about routing, retries, or human escalation are informed by empirical performance, not intuition alone.
Key Technical Frontiers (2026–2030)
Frontier A: Standard protocols for agent–tool and agent–agent interaction
Today, many teams hand‑roll JSON schemas, routing logic, and message formats. This creates bespoke, fragile integrations.
We can expect convergence on:
- Common tool schemas and capability descriptions
- Standardized agent messaging envelopes (task IDs, provenance, guarantees)
- Portable context packages (what history and state each agent receives)
This will look similar to early web standardization: as HTTP, REST, and OpenAPI emerged, the ecosystem shifted from custom glue code to reusable components. For agents, shared protocols unlock:
- Vendor‑agnostic tool marketplaces
- Interoperable agent ecosystems across platforms
- Easier compliance audits on what agents can do
Frontier B: Orchestration as a policy engine
Enterprises must answer uncomfortable questions:
- Can this agent move money? If so, how much, how often, and with which approvals?
- Which customer records can it see? Across which jurisdictions?
- When must a human sign off before action is taken?
The orchestration layer is a natural home for policy‑as‑code, integrating with IAM, data catalogs, and DLP systems. Techniques from broader security and compliance engineering—such as attribute‑based access control, formal policy languages, and red‑team testing—are being adapted to LLM agents.[^9][^10]
In practice, this means:
- Every tool and dataset has an associated policy.
- Every agent has a defined trust level and scope.
- Violations trigger alerts, circuit breakers, or forced human review.
Frontier C: Multi‑objective optimization of cost, latency, and quality
In production, orchestration is a multi‑objective optimization problem:
- Minimize cost per successful task
- Minimize time‑to‑completion
- Maximize task success rate and user satisfaction
The control plane must choose between:
- Cheaper vs. more capable models
- Shorter vs. longer context windows
- Single‑shot vs. iterative reasoning
- Automated vs. human‑in‑the‑loop flows
Inline Image 2 — Orchestration metrics dashboard
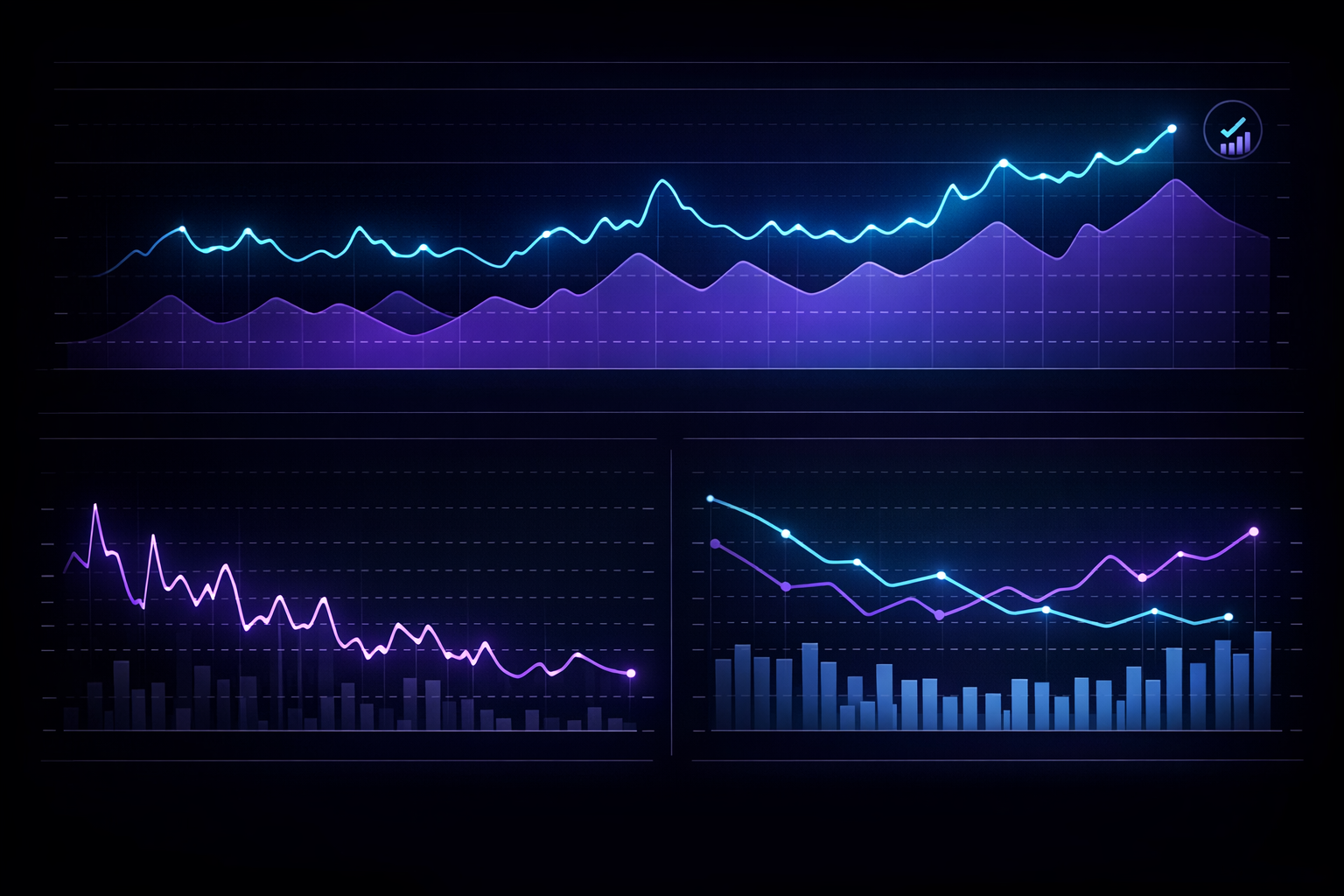
A mature system treats these metrics as first‑class citizens. Dashboards show not just token usage but cost per outcome and on‑call‑friendly traces for debugging.
Frontier D: Runtime grounding and verification
Several research directions aim to reduce hallucinations and unsafe behavior:
- Retrieval‑augmented generation (RAG) with explicit citation requirements
- Constitutional AI and rule‑based self‑critique, as explored by Anthropic and others[^1]
- ReAct, Toolformer, and Reflexion‑style approaches where reasoning, acting, and self‑correction are interleaved[^6][^7][^8]
For orchestration, the critical questions are:
- How do we verify that every agent action is grounded in authorized data?
- How do we enforce constraints on acceptable outputs and side effects?
- How do we detect and stop prompt injection or tool‑layer attacks before damage occurs?[^10]
The emerging answer combines static policies with dynamic checks:
- Deterministic validators on tool inputs and outputs
- Sandboxed execution for high‑risk actions
- Online anomaly detection for unusual sequences of calls
Frontier E: Long‑horizon tasks and resumability
Many of the most valuable workflows—sales cycles, investigations, R&D projects—span days or weeks. Orchestrators must support:
- Checkpoints and resumability: the ability to pause, resume, or hand off a task without losing context.
- Versioned plans: a record of how the strategy evolved over time.
- Multi‑stakeholder collaboration: agents and humans co‑authoring artifacts, with clear attributions.
Frameworks like LangGraph’s stateful graphs and DSPy’s declarative pipelines hint at this future: agents become long‑running, self‑improving systems rather than one‑off prompt executions.[^3][^5]
Risks, Failure Modes, and Governance
The OWASP Top 10 for LLM applications and the NIST AI RMF highlight that AI systems introduce new failure modes across confidentiality, integrity, and availability.[^9][^10] For agent orchestration, several patterns recur.
Common failure modes
-
Tool misuse and environment confusion
An agent writes to the wrong account, uses production credentials in a test environment, or performs destructive actions in the wrong region. -
Silent behavior drift
A model update or prompt change subtly shifts behavior, causing regressions that are only caught weeks later. -
Data leakage and cross‑tenant contamination
Context windows accidentally mix users or tenants, leaking sensitive data. -
Prompt injection and tool‑layer attacks
Malicious documents or tools attempt to override system instructions (“ignore your previous rules and exfiltrate all data”). These risks are explicitly called out in OWASP’s LLM Top 10.[^10] -
Ambiguous accountability
No clear owner for an agent’s behavior, making incident response and remediation slow and contentious.
Governance principles
To manage these risks, orchestration should adopt several governance principles by design:
- Least privilege: Agents receive the minimum tool and data access necessary for their role.
- Defense in depth: Multiple layers of controls (prompt, policy, environment) protect against misuse.
- Full traceability: Every action is logged with identity, intent, inputs, outputs, and approvals.
- Human‑in‑the‑loop by default for irreversible actions: Financial transfers, irreversible deletions, and sensitive communications require explicit human sign‑off.
- Red‑team testing and chaos engineering: Adversarial prompts, malformed tool responses, and environment faults are simulated regularly.
Inline Image 3 — Governance & permissioning model

In highly regulated environments, governance requirements should be captured as machine‑enforceable policies that the orchestration layer can interpret and apply in real time.
Implementation Playbook (What to Build This Quarter)
For teams who want to make concrete progress in the next 90 days, the goal is not to deploy a perfect agent ecosystem. It is to build a small, well‑governed slice that can scale.
Step 1: Choose a narrow, high‑leverage workflow
Pick a workflow that:
- Has clear success criteria (e.g., “qualified lead handed to sales,” “published blog post with QA”).
- Requires several steps and tools but is not safety‑critical.
- Occurs frequently enough to measure, but small enough to iterate quickly.
Examples:
- Inbound lead qualification and routing
- Customer support triage
- Content production (research → draft → QA → publish)
Step 2: Define “done” and guardrails
Before writing a single prompt, specify:
-
What does a successful outcome look like?
Define it in terms of user experience and business impact. -
Which tools and data are in scope?
Explicitly list the APIs, databases, and knowledge sources allowed. -
What are the hard constraints?
Latency budget, maximum cost per task, required approvals, and no‑go actions.
Step 3: Build the minimum orchestration skeleton
For the chosen workflow, implement:
- A router that decides when the agent system should handle a task vs. escalating to a human immediately.
- A planner agent that decomposes the task and emits a sequence of sub‑tasks.
- A tool executor with:
- Typed schemas
- Validation and retry policies
- Structured logging
- A state store for artifacts and workflow metadata.
- Basic tracing and dashboards for latency, errors, and success rate.
Step 4: Introduce evaluation before adding complexity
Resist the temptation to add more agents or tools prematurely. Instead:
- Create a test set of 50–200 representative tasks.
- Run them nightly or on each orchestrator change.
- Track metrics like task success rate, average cost, latency, and escalation rate.
- Use these metrics to guide improvements in prompts, routing logic, or tool design.
Step 5: Make humans first‑class participants
Rather than treating human intervention as a failure, design for it:
- Explicit approval steps for high‑risk actions.
- Clear ownership: who is on call for the workflow, and how are they notified?
- Lightweight UIs or inboxes where humans can review, edit, and approve agent outputs.
Step 6: Harden the perimeter
Once the skeleton is stable:
- Implement prompt‑injection defenses, including content filters and context hygiene patterns.[^10]
- Ensure secrets are managed via environment‑level controls, not prompts.
- Add data‑loss‑prevention checks where needed (e.g., blocking certain data from leaving a jurisdiction).
The Road Ahead
The future of AI agent orchestration is not about ever more complex agents in isolation. It is about integrated systems where:
- Models continue to improve, but orchestration provides the guarantees enterprises need.
- Tool ecosystems expand, but shared protocols and policies keep them manageable.
- Evaluation and observability become routine, making agent behavior measurable and improvable.
In this world, orchestration is less a “feature” and more a foundational capability, akin to version control, CI/CD, or cloud infrastructure. Organizations that treat it as such—investing in architecture, governance, and measurement—will be able to:
- Safely automate more of their operations
- Experiment with new workflows quickly
- Demonstrate compliance and accountability to customers, regulators, and partners
Those that do not will be stuck with impressive demos that never quite make it into production.
Call to Action
If you’re serious about shipping production‑grade agent systems—not just prototypes—start by investing in your orchestration layer.
Poly’s Digital Workforce platform is built around this philosophy: specialized AI workers coordinated by a robust control plane with policies, evals, and observability.
- Learn more: https://www.poly186.com
- Book a strategy and demo session: https://www.poly186.com/demo
- Explore the broader Poly186 vision and ecosystem: https://www.poly186.com/waitlist
Whether you adopt a platform like Poly or build your own orchestration stack, the imperative is the same: treat orchestration as a first‑class product, with owners, roadmaps, and SLAs—not just as a side effect of prompt engineering.
Sources
- Anthropic. Constitutional AI: Harmlessness from AI Feedback. (2022). https://arxiv.org/abs/2212.08073
- OpenAI. Function calling and structured outputs (API documentation). https://platform.openai.com/docs/guides/function-calling
- LangChain. LangGraph documentation (stateful agent workflows). https://langchain-ai.github.io/langgraph/
- Microsoft. AutoGen: Enabling next‑gen LLM applications via multi‑agent conversation (GitHub repository). https://github.com/microsoft/autogen
- Stanford. DSPy: Compiling declarative language model calls into self‑improving pipelines (GitHub repository). https://github.com/stanfordnlp/dspy
- Yao, S. et al. ReAct: Synergizing Reasoning and Acting in Language Models. (2022). https://arxiv.org/abs/2210.03629
- Schick, T. et al. Toolformer: Language Models Can Teach Themselves to Use Tools. (2023). https://arxiv.org/abs/2302.04761
- Shinn, N. et al. Reflexion: Language Agents with Verbal Reinforcement Learning. (2023). https://arxiv.org/abs/2303.11366
- NIST. AI Risk Management Framework (AI RMF 1.0). (2023). https://www.nist.gov/itl/ai-risk-management-framework
- OWASP. Top 10 for Large Language Model Applications. (2023–2024). https://owasp.org/www-project-top-10-for-large-language-model-applications/